충북대학교 공동연수원 IoT 기반 스마트솔루션 개발자 양성과정
3주가 끝났습니다
곽내정 교수를 시작으로 약 2주간의 연수과정으로 마무리되었다.
C의 맛을 느끼기 시작했을 때 나는 그것이 끝난 것처럼 느꼈습니다.
C는 Python과 많은 유사점과 공통점을 공유합니다.
어떤 부분은 편하고 프로그래밍 같은 느낌이라 멋있었어요
언제부턴가 내가 왜 이렇게 편한 걸 쓰는지 느꼈다.
마치 곽내정 교수님의 마지막 수업처럼
기본 머신러닝 환경 설정과 Jupyter 노트북을 통한 다양한 목업을 사용했습니다.
이 점을 요약하고 싶습니다.
기본 환경 설정
먼저 기계 학습을 위해 Python을 사용해야 합니다.
Python에서 실행되는 다양한 라이브러리를 설치해야 합니다.
이렇게 하려면 Anaconda를 설치해야 합니다.
(맥에서 사용했을때 아나콘다는 무거워보이고 경로가 막혀서 사용하기 싫었습니다.
어쩌면 내 기억에서 방금 venv로 가상 환경 폴더를 만들고 실행했을까요?
가상 환경을 만들 때 Anaconda 만 사용했습니다.
이 부분만 필요하다면 앞으로 Anaconda를 사용할 필요가 없다고 스스로 판단)
Google 검색에 anaconda를 입력하면 나타납니다.
아래 링크에서도 접속 가능합니다
https://www.anaconda.com/products/distribution
아나콘다 | 아나콘다 분포
Anaconda의 오픈 소스 배포판은 단일 컴퓨터에서 Python/R 데이터 과학 및 기계 학습을 수행하는 가장 쉬운 방법입니다.
www.anaconda.com
환경 변수 경로 설정
경로 설정이 잘못된 경우가 있어서 에디터마다 파이썬 버전이 다르거나
Python을 찾을 수 없는 경우가 있습니다.
Anaconda의 경우 설치 후 위의 설정으로 실행
문제없이 진행됩니다
Python을 찾을 수 없거나 경로가 지정되지 않았다는 오류 메시지가 표시되는 경우
설정 방법은 아래 링크를 참고해주세요
가상 환경의 기본 구성을 따라하자
https://mealhouse.7
Tensorflow 환경 설정 및 설치(Windows)
ⓐ Tensorflow 실행을 위한 가상 환경 설치 및 설정 단계를 기록 및 공유 ⓑ 듀얼 OS로 Windows/Mac 환경 설치 과정 ⓒ Bugs and share my experience * Python 기본 설치
mahlhaus.tistory.com
가상 환경 구축 후
데이터 분석 및 모델 구축을 위해 Jupyter Notebook을 실행해야 합니다.
위의 링크를 참고하시면 아래와 같은 라이브러리가 설치되어 있을 것입니다.
핍 설치 ipykernelpython -m ipykernel install –user –name 가상 환경 이름 –display-name “가상 환경 이름”conda install tensorflow==version: (사용 중인 Python 버전과 호환되는 tensorflow 버전)
핍 설치 주피터
그 중 ipykernel과 tensorflow는 다음에 해봐야 겠습니다.
먼저 Jupyter를 설치하고 실행하십시오.
Anaconda 가상환경에 접속 후 jupyter notebook 명령어 입력

콘다 환경 목록
콘다 정보 –envs
이 명령은 가상 환경의 위치와 이름을 보여줍니다.
생성한 가상 환경의 이름으로 명령을 입력합니다.
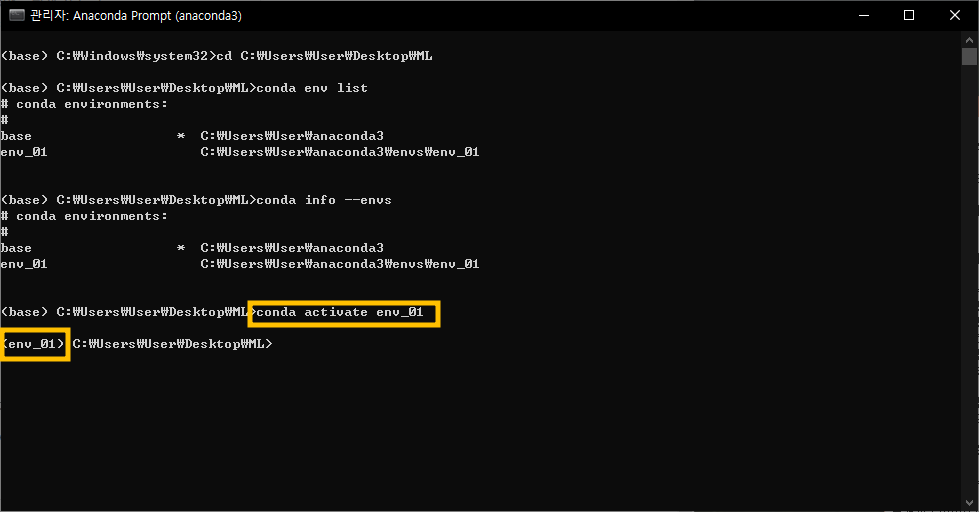
conda는 “가상 환경 이름”을 활성화합니다.
명령을 입력하면 왼쪽에서 볼 수 있듯이
가상 환경에 성공적으로 진입하면 가상 환경의 이름이 변경됩니다.
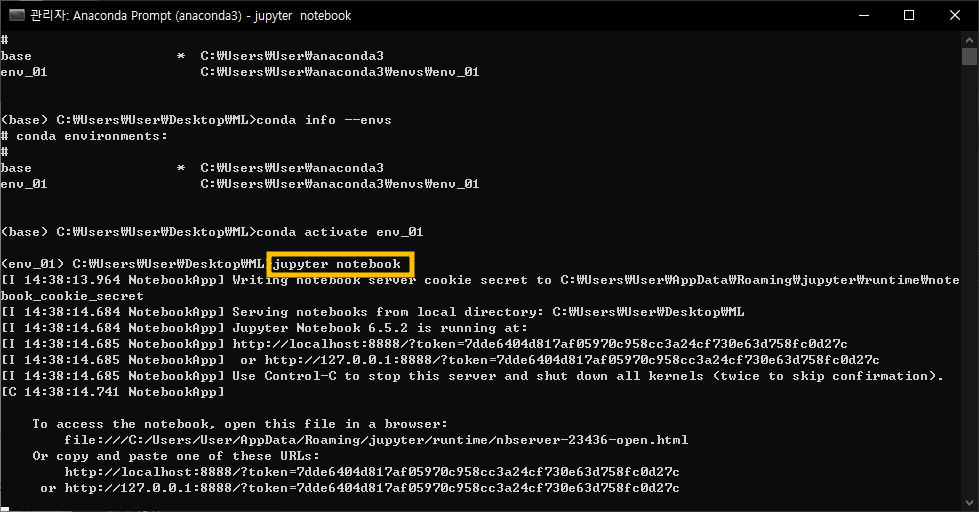
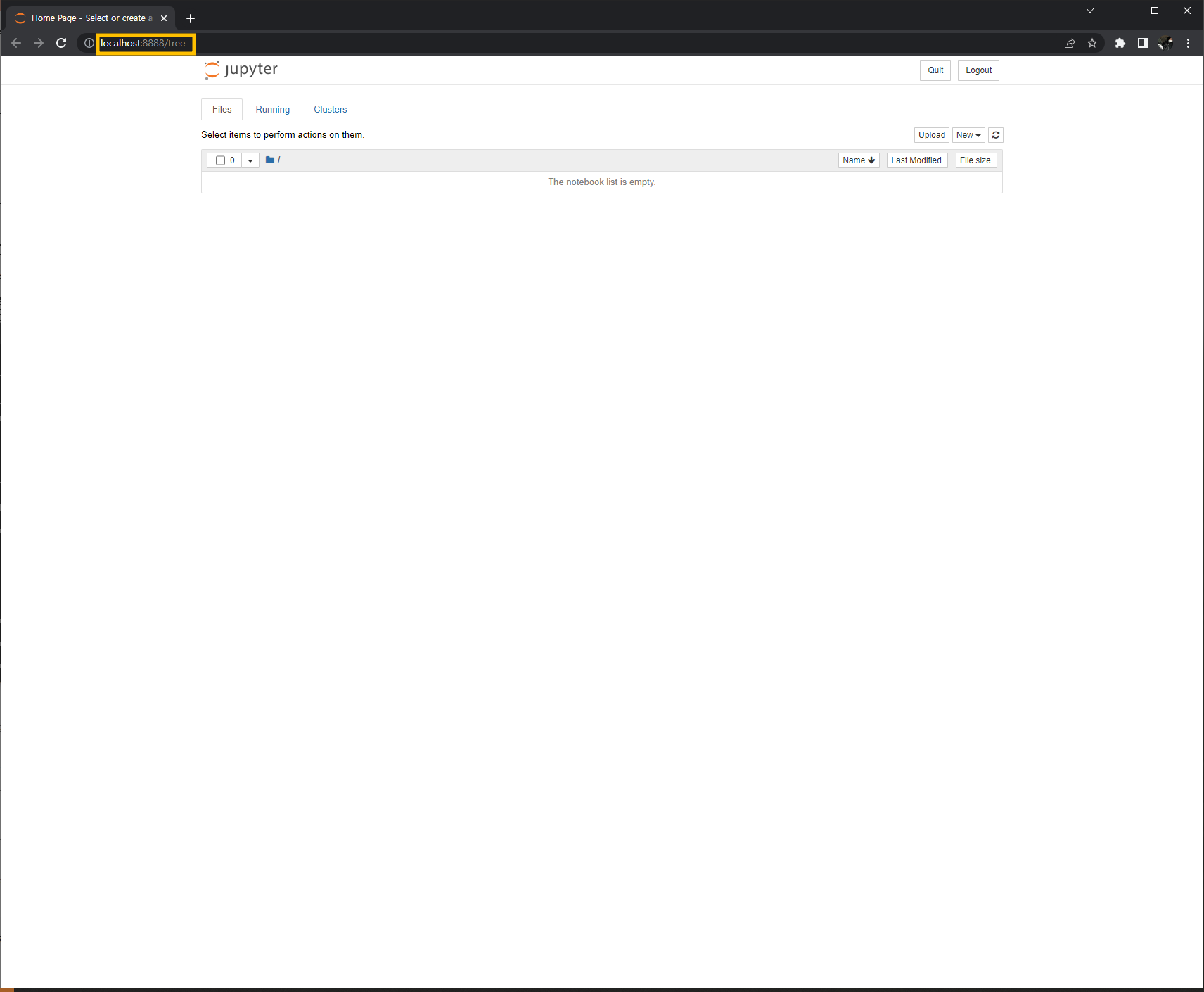
Jupyter Notebook은 웹 브라우저에서 실행되기 때문에,
위와 같이 생겼습니다
++ 기본적으로 Jupyter Notebook이 실행 중인 경우 기본 폴더 위치는 C:\Users\user 폴더입니다.
따라서 여기에서 실행하면 파일이 매우 지저분한 모양이 될 수 있습니다.
마지막으로 경험 정리가 어려웠는데,
이를 해결하려면 원하는 위치에 폴더를 생성합니다.
cd 명령어로 폴더 위치 입력 후 가상환경 진입 전
가상 환경으로 이동 -> Jupyter Notebook 실행
단계를 거친 후 깨끗한 형식으로 파일 생성을 시작할 수 있습니다.
Jupyter 노트북 사용
머신러닝을 진행하기 전에 가장 기본적인 회귀분석이나
다른 이론적인 부분은 생략합니다.
충북대학교 공동연수원에서 스마트 IoT 기반 솔루션 개발자 교육과정 중
그 의미를 이해하기 위해 우리가 배우고 개발한 코드를 분석해 봅시다.
모든 코드를 먼저 입력하십시오.
코드 분석을 한 줄씩 살펴보겠습니다.
※ 설치된 라이브러리
numpy scipy matplotlib 스파이더 팬더 seaborn scikit-learn h5py
라이브러리가 설치되어 있지 않은 경우 명령 프롬프트 창(Anaconda 가상 환경)에서
pip install을 통해 설치
import numpy as np
from sklearn import linear_model
regr = linear_model.LinearRegression()
X = ((163), (179), (166), (169), (171))
y = (54, 63, 57, 56, 58)
regr.fit(X, y)
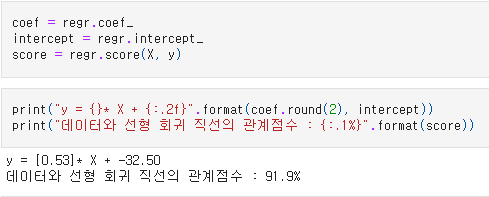
coef = regr.coef_
intercept = regr.intercept_
score = regr.score(X, y)
print("y = {}* X + {:.2f}".format(coef.round(2), intercept))
print("데이터와 선형 회귀 직선의 관계점수 : {:.1%}".format(score))
# ===== 출력결과 =====
y = (0.53)* X + -32.50
데이터와 선형 회귀 직선의 관계점수 : 91.9%
# ====================
import matplotlib.pyplot as plt
plt.scatter(X, y, color="blue", marker="D")
y_pred = regr.predict(X)
plt.plot(X, y_pred, 'r:')
unseen = ((167))
result = regr.predict(unseen)
print(f"OO이의 키가 {unseen}cm 이므로 몸무게는 \
{result.round(1)}kg으로 추정됨")
# ===== 출력결과 =====
OO이의 키가 ((167))cm 이므로 몸무게는 (56.2)kg으로 추정됨
# ====================
regr = linear_model.LinearRegression()
X = ((168, 0), (166, 0), (173, 0), (165, 0), (177, 0), (163, 0),\
(178, 0), (172, 0), (163, 1), (162, 1), (171, 1), (162, 1), \
(164, 1), (162, 1), (158, 1), (173, 1))
y = (65, 61, 68, 63, 68, 61, 76, 67, 55, 51, 59, 53, 61, 56, 44, 57)
regr.fit(X, y)
print("계수 : ", regr.coef_)
print("절편 : ", regr.intercept_)
print("점수 : ", regr.score(X, y))
print("OO이와 XX의 추정 몸무게 : ", regr.predict(((167, 0), (167, 1))))
# ===== 출력결과 =====
계수 : ( 0.74803397 -7.23030041)
절편 : -61.227783894306384
점수 : 0.8425933302504424
OO이와 XX의 추정 몸무게 : (63.69388959 56.46358918)
# ====================
x = np.array((1, 4.5, 9, 10, 13))
y = np.array((0, 0.2, 2.5, 5.4, 7.3))
print(x)
print(y)
( 1. 4.5 9. 10. 13. )
(0. 0.2 2.5 5.4 7.3)
regr = linear_model.LinearRegression()
x = x(:, np.newaxis)
print(x)
regr.fit(x, y)
print("w = ", regr.coef_.round(2), \
"/ b = ", regr.intercept_.round(2))
# ===== 출력결과 =====
(( 1. )
( 4.5)
( 9. )
(10. )
(13. ))
w = (0.63) / b = -1.65
# ====================

numpy를 np로 가져오기 : numpy 라이브러리를 호출하고 np라는 이름으로 호출하는 것을 의미합니다.
sklearn import linear_model에서 : sklearn에서 linear_model 호출(선형 회귀)
X, Y 무작위 데이터를 생성하고 데이터에 계속 맞춤
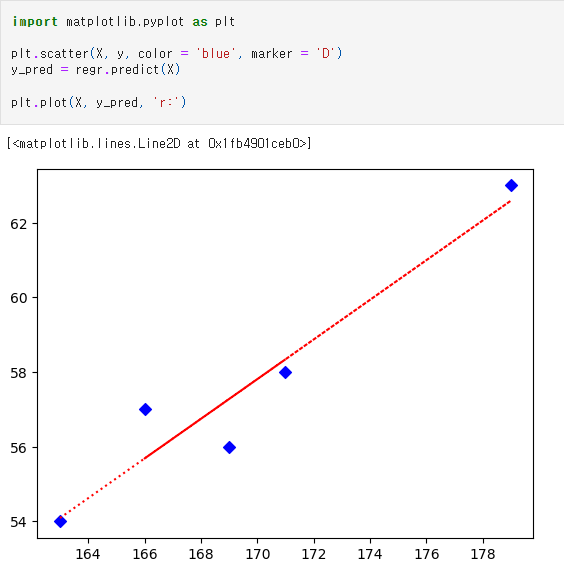
matplotlib.pyplot을 plt로 가져오기: 차트를 그리기 위한 라이브러리 호출
plt.scatter: matplotlib에서 산점도를 그리기 위한 함수
plt.plot: 선 그리기 기능
예측(x)의 값을 LinearRegression 모델에 삽입하고 변수(y_pred)로 설정합니다.
plt.plot 함수에서 기존의 x값과 예측된 y값(y_pred)을 플롯하면,
위와 같은 이미지가 나옵니다
파란색 다이아몬드 플롯은 산점도입니다.
그 이후의 코드는 위와 동일한 형식을 가지며,
numpy 배열만 사용하지만 LinearRegression 모델을 사용하므로 동일합니다.
천천히 하나하나 살펴보자.